The Research Data and Software (RDS) team at the TU Delft Library has been undergoing an extensive grow during the last half an year. With the last new team member starting in mid-January 2024, we are very proud to present the complete team organization. For more information on the Research Services department at TU Delft Library, please visit this blog.
Research Data Management & Digital Skills Training
The training team is led by the coordinator and consists of 4 trainers, 1 educational advisor and 1 training assistant.
They coordinate, organise and run training for PhD candidates and researchers (and MSc students in some cases)
They collaborate with stakeholders from library, TU Delft and external on new training development and integration.
Data Stewardship
RDS provides the coordination of the TU Delft Data Stewardship. The Data Stewardship coordinator and the library Data Steward are in the Data Stewards team together with all faculty Data Stewards.
The coordination is twofold: coordination within the Data Stewards team and coordination with all relevant university service teams.
The Library Data Steward facilitates on all innovation projects within the Data Stewards team, and also provides the functional management of related applications (DMPonline, ELNs).
Digital Competence Centre
The RDS team is part of the TU Delft Digital Competence Centre (DCC) in collaboration with ICT innovation. Four data managers from RDS work are members of the DCC team and provide hands-on support on open and FAIR data management to researchers. The daily operation of the DCC team falls under the coordination of DCC coordinator from ICT innovation.
Innovation
The RDS team runs innovation projects which aims to pilot new services/applications, explore solutions to emerging issues or address future directions in the domain of research data and software management. Three current projects are supported by the TU Delft Open Science program:
iRODS pilot (collaboration with ICT innovation)
Guidelines for research data and software management in various research fields
Research data and software peer review (collaboration with TU Delft OPEN Publishing)
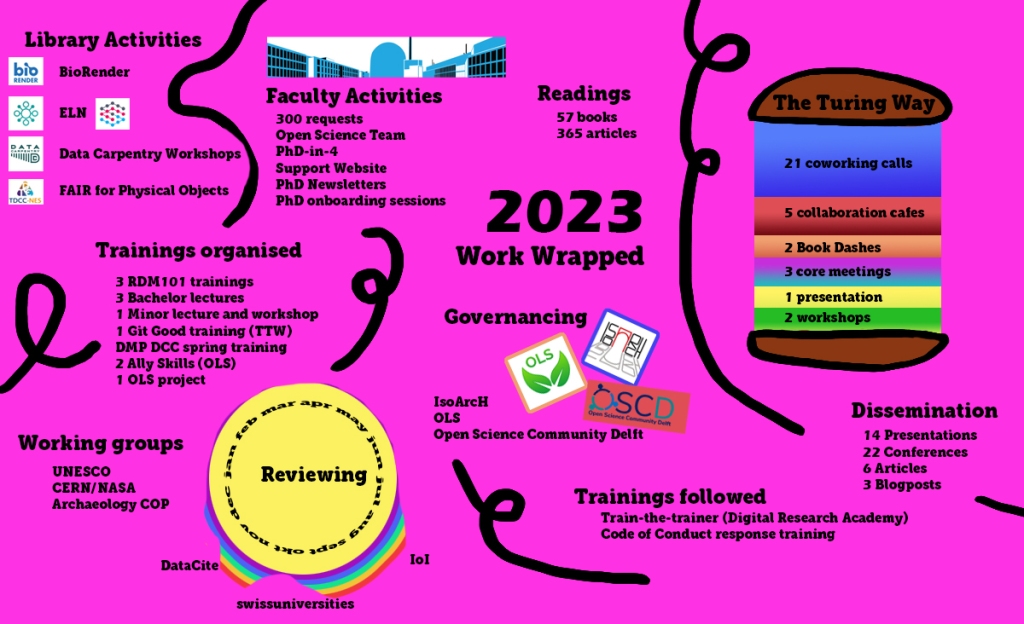
After writing overviews for 2021 and 2022, I decided to wrap 2023 up in a different way! If you’re not a Spotify user the overview might look a bit… interesting:
Some more details:
Faculty Activities
300 requests
Open Science Team
PhD-in-4
Open Science Support website now has 105 posts! (Not all are finalised and can be indicated with WIP – work in progress)
Discussions at the Leiden University & Elsevier Symposium on Digital Sovereignty, held on 29 November, illustrated how complex yet necessary this relatively new concept of digital sovereignty is. Even the representative from Microsoft, was convinced of the importance of the term. For him, it is a way for gaining and securing customers’ trust, privacy and security for the digital services they provide (and, of course, making a profit)
Azar Koulibaly from Microsoft giving his presentation on ‘Public Values in the Digital Age: Challenges and Opportunities for the Netherlands‘
In the Dutch university sector, we already have some projects that are inspired by the broader discussion over digital sovereignty. There is the Public Spaces movement, largely initiated by the broadcasters, but with some interest from higher education. Surf is making various eye-catching projects, such as its own Large Language Model, and has started an Open Research Information Agenda. And 4TU.ResearchData’s Djehuty data repository software openly invites contributions from the research community. There are others.
But these are still relatively isolated steps.
Within the university / research library sector we are still missing the crucial conversation about how we can work together, and in what areas we want to prioritise.
As background context, the diagram by Bianca Kramer and Jeroen Bosman from 2019 remains a relevant depiction of the landscape of research tools. (their related slides anticipate nearly all of this blog post). It does not depict all the digital services that university researchers make use of it – far from it – but it nevertheless highlights the complexity.
Most importantly, the diagram demonstrates the various arenas within the researcher lifecycle where the university library sector have ceded (consciously or not) digital sovereignty to commercial actors.
Currently, most universities engage, in a contractual sense, with the providers of these servers in an individual context. University A does a deal for Dimensions, and University B does a deal for Mendeley. This is opposed to deals done for access to ‘traditional’ publishing, where the Dutch universities have a history of organising collective agreements with the larger publishers
It seems to me that there is plenty of opportunity to work together to deal with this challenge more effectively: in the metaphor of speaker Ron Augustus from Surf, making honey by acting as bees in a colony.
Can we come together rather than work on this independently?
Some of the possible actions for a collective group might be:
Defining the key areas on the researcher lifecycle (or indeed for any digital service) where we want to secure (or regain) our digital sovereignty
Defining how we want to enact that digital sovereignty
By continuing to have contracts with commercial players, but to do so at a collective level and informed by values (such as the Seven Guiding Principles for Research Information)
By working together to create our own services to replace the commercial services
By make sustained, strategic contributions to existing open source services at a global level (a simple example of which is the contributions made to the governance structure of the service Open Knowledge Maps). These contributions could be technical, financial or intellectual
By making sustained, strategic contributions to open source networks such as SCOSS or Invest in Open
And finally, defining what we mean by we. Universities? University Libraries? Medical Centres? Research Units? Or maybe even public sector organisations (broadcasters, museums etc)
As the Leiden symposium demonstrated, digital sovereignty is a problem you can drown in – overwhelmed by its size and complexity – and ending up going nowhere.
To avoid this, and to ensure our digital sovereignty, we need to make collective priorities.
The Open Science Festival was hosted by the Erasmus University in Rotterdam on 31 August 2023. Over 400 people registered for the event, ranging from experts in Open Science to those interested in learning about Open Science. It includes researchers, research support staff, and suppliers. The full programme includes presentations, plenaries, and networking time.
Reflection on Opening Session
The opening session was a nice confirmation of steps that TU Delft is taking in the right direction towards open by establishing Data Stewards and by creating grassroots funding opportunities for Open Science. The opening session was lead by Esther van Rijswijk and Antonio Schettino and included Annelien Bredenoord, Rector Magnificus of Erasmus University Rotterdam.
Open Science though tends to have more grassroot pilots in various stages with hopes of becoming embedded into an ecosystem. Before moving to the Netherlands, I supported virtual exchanges which often are grassroot pilots which hope to become embedded into an ecosystem between multiple universities. Due to my prior work, open education sparked my interest, particularly Open Educational Practice (OEP). Thus for me, Open Science feels like a more established infrastructure to empower research advancements. Ironically, Erasmus is globally known as a symbol of student mobility and thus is often the name leading virtual exchanges such as the Erasmus Virtual Exchanges.
Open Science events are an excellent space to see how others are collaborating and what advancements there are in the field. It’s also where you can foresee hurdles along the path of advancements.
The Open ebook from 2017 by Rajiv Jhangiani and Robert Biswas-Diener implied that OEP and Open Education overshadow Open Educational Resources (OER) which often take form in MOOCs in Open Education. For Open Science, the format of OER is often software such as a tool which some called Open Education Tools (OET) for a time, but that has seemed to disappear or reverted back to OER.
Session reflections
The first session I attended was Beyond Access: Making Research Discoverable, Accessible and Inclusive for All. This session speakers werePeter Kraker (Open Knowledge Maps), Astrid van Wesenbeeck & Martijn Kleppe (KB, National Library of the Netherlands), Maurice Vanderfeesten (VU University Library). To showcase the issue of paywalls, the first speaker was a primary school teacher who showcased the need for open access. In short, teachers do not have access that they might have had as a student through a university library. The example given was if the teacher reads a book with references that do not have open access, then they need to purchase subscriptions. A fundamental problem in the education system is that elementary and secondary schools do not have access to research that could provide professional development.
Following that, the struggle that the national library system has in improving services beyond creating awareness became more evident.
Next in that session was a demo of Open Knowledge Maps and then OpenAire. Both offer much potential to campus. Open Knowledge Maps seems to be a nice way to see what themes are in a repository or collection that we maybe didn’t notice yet. It could also be a nice way to allow end-users to make their own selection of items they want to display/save from our repository.
2.3 Connecting FAIR data with OPEN ACCESS Publications Project
This session was presented by Madalina Fron and Zahra Khoshnevis (TU Delft). The project was supporty by Yan Wang, Just de Leeuwe, and Frederique Belliard (TU Delft). This TU Delft initiative was a great starter project from Bachelor level students. They presented that 82% of peer-reviewed articles and 71% of conference papers are Open Access (OA), but that we lack numbers on open data. The project aims to review the connection between OA and Findable Accessible Interoperable and Reusable (FAIR).
The questions and answers posed in the session were difficult to follow by the audience, but were still relevant to the field. This session made me wonder how we train end-users for uploading and how we advise visitors of licensing and if there is room for improvement to embed training and advise in our repository further. The speakers brought up metadata and seemed to believe in sound metadata, but I also wonder based on the perception in the room what role automating metadata and checking and auto improving metadata is already expected from end-users. Perhaps current expectations are that showcased technologies at such events like these are already embedded into current tools.
3.4 Recognition & Rewards: Open & Responsible Research Assessment
This session was presented by Lizette Guzman-Ramirez, Nami Sunami and Jeffrey Sweeney (EUR). This final presentation offered an intriguing solution for recognition. They explained their recognition and rewards badging system and asked the audience for input on improving the badges. However, one audience member sparked a debate by asking if badges replace the current problematic system with another that simply repeats a checklist but offers a different list with different people giving the checks. The debate seemed to question the reasoning behind rewards and recognition. It also seemed to question how such a system relates to empowering researchers to advance their careers in a different way or provide transparency about their career opportunities. If we want to help researchers advance their career in a personalized way, could virtual career advice be applied to a researcher profile to improve the career opportunities based on their outputs, education, and other skills noted in a researcher profile? I wonder if something could be explored in that space in addition to the rewards and recognition programmes or as part of them.
Reflections on Open Education and Open Science events and Future Infrastructure Predictions
While I typically attend Open Education events, I’m new to attending Open Science events. Here are my reflections on Open Education events and future predictions.
Open Education events tend to be more about Massive Open Online Courses (MOOCs), although it is much debated if they are really massive since the original numbers of participants have decreased since the early years of MOOCs. In 2016, the trend in MOOCs predicted they would replace lifelong learning and provide flexible professional development (Castaño-Muñoz, Kreijns, Kalz, 2016). This prediction seems to be quite accurate. Willem van Valkenburg predicted in 2018 that “as more universities and higher education systems begin offering their degree programs online, we could be moving towards a single, global system of higher education” (The 9th TCU International e-Learning Conference in Thailand in 2018 (Pickard, 2018). I believe this prediction will also take place; it is only a question of when.
With these reflections in mind, I attended the Open Science Festival hoping to hear future predictions in the field and also hear how we’ve learned from the recent past, from predictions that missed the mark. I missed the closing due to last minute scheduling and thus missed the likely future predictions. The trends seem to be that the younger generation already assumed Open Science is a standard and they do not seem to be aware how much effort it took to get here. Across the field, there seems to be common support issues for Open-Source pilots seeking to become established services. Infrastructure for OER within Open Science is much needed. I look forward to future Open Science events and seeing the future advancements!
The three-day event (20 June) kicked off with a symposium ‘Perspectives on teaching reproducibility’ organised by Sheffield Methods Institute (SMI) in collaboration with the University Library and Open Research Working Group (ORWG), and led by Aneta Piekut (SMI) and Jenni Adams (Library). The activities focused on incorporating reproducible methods in teaching reproducible research. It was attended by approximately 40 participants.
In Carlos’s talk (https://zenodo.org/record/8158825), he spoke about Delft’s commitment to doing science responsibly in a way that maximises the positive benefits to society. This symposium provided an excellent opportunity for us to illustrate with examples how we motivate, and provide practice opportunities to researchers to engage them in learning about the benefits of reproducibility.
The Symposium stimulated interdisciplinary exchange of best practice in doing and teaching open research. The participants discussed different approaches on embedding open science principles in taught programmes in such disciplines, like computer science (Neil Shephard, University of Sheffield), engineering (Alice Pyne, Univ. of Sheffield and Carlos Utrilla Guerrero, TU Delft Library), social sciences (Jenniffer Buckley, Univ. of Manchester and Julia Kasmire, UK Data Service, Jim Uttley, Univ. of Sheffield), geo-data-science (Jon Reades and Andy MacLachlan, UCL), psychology (Marina Bazhydai, Lancaster Univ. and Lisa DeBruine, Univ. of Glasgow). Project TIER’s Directors also gave the first keynote speech arguing in favour of saturating quantitative methods instruction with reproducibility. In the second keynote of the day, Helena Paterson from School of Psychology & Neuroscience at the University of Glasgow reflected on the School journey of redesigning the psychology undergraduate and postgraduate curriculum to focus on teaching reproducible methods and analysis.
On day two, (21 June) Norm and Richard delivered a UKRN accredited workshop (Repository: https://osf.io/3jwyz/) on integrating principles of transparency and reproducibility into quantitative methods courses and research training. During the final day (22 June) Project TIER’s Directors were available for individual and small-group meetings with instructors interested in introducing reproducible methods into their classes.
The conference and workshop was a great opportunity to get to know practices and use cases of embedding open science and reproducible research in teaching activities in different fields. A useful piece of advice from several attendees about effective methods for teaching reproducibility is that today’s students (MSc and BSc) are potentially tomorrow’s researchers, and so integrating reproducibility into the undergraduate curriculum will be crucial in promoting and implementing reproducible practices in the long term. This is in line with the work of the TU Delft Library’s Data Literacy Project, an initiative of the Open Science Programme that launched in March 2023. The Data Literacy Project is investigating how to integrate skills on data literacy and open science practices into the BsC and MsC programmes at TU Delft. Please contact project leader Paige Folsom for more information about the project: P.M.Folsom@tudelft.nl.
However the lack of sustainable Data Steward capacity, either in terms of funding or competent personnel, seems to be a common challenge for almost all institutions, regardless of how well the Data Stewardship is established there. There have been several initiatives at both strategic and operational levels with the purpose of recognizing and rewarding Data Stewardship or different types of research contributions, e.g. the position paper ‘Room for everyone’s talent’ in the Netherlands, the EOSC/RAD open calls and so on. Nevertheless, these initiatives either need to be operationalized or could only provide a project-based boost. The community and institutions still seek a more systematic approach to establish Data Stewardship as a profession in the academic system.
The Recipe
One brilliant idea from the RDM team at the KTH Royal Institute of Technology in Sweden may serve as a pragmatic recipe for this demand:
Training doctoral students to work formally as Data Stewards
during the course of their PhD with extra paid time.
Immediate benefits
Many doctoral students already undertake informal work that mirrors that of Data Stewards, and are embedded in the day-to-day research data management of the projects they are involved in. As current RDM support staff at many universities can also attest to, doctoral students are often enthusiastic workshop participants, and more than occasionally need more RDM-specific support than their supervisory team can provide. Involving them in a more proactive role brings immediate benefits to the Data Stewardship ecosystem.
Voluntary but rewarded
The recipe in the works at KTH would give doctoral students professional skills development in RDM and data stewardship and more formal recognition for work that many of them already do. The proposed idea will be voluntary but rewarded, meaning:
Doctoral students are free to choose to join this programme, and be credited with the prolongation of their contracts for the time spent.
They would attend compulsory training that touches on RDM, open science, and data stewardship, which would ideally be credited as part of their course load.
They would be part of a university-wide RDM network that supports each other and works together on improving awareness in research communities.
A larger pool of Data Stewards
Although doctoral students are not often permanent additions to research teams, the recipe could allow for a larger pool of data stewards at a HEI (Higher Education Institution) than otherwise allowed, if relying on central or institutional administration to allocate funds for data stewards. We see that in many research areas, there is a growing need for more hands-on RDM support services that are closely connected with research teams. Doctoral students in Sweden are allowed to undertake at least 20% of institutional administrative or teaching activities over the course of four years of full-time employment. By including data stewardship as one of these activities, HEIs might be able to better meet the needs of data-driven research areas in providing RDM support.
Upskilling researchers and competency building
This recipe also addresses one of the common challenges faced by RDM support staff in building competencies and upskilling researchers in RDM. Training doctoral students as data stewards embeds RDM training in research communities, educates future researchers in RDM, and gets them working operatively with RDM early on. This RDM support that is embedded in research teams addresses some of the challenges described in Professionalizing Data Stewardship in the Netherlands, by working with established, or at least developing, relationships. This is similar to Aalto University’s Data Agents, who are typically postdoctoral researchers or staff scientists and work 10 – 50% as data agents.
Long term benefits
This recipe further offers a few solutions to some of the prevailing challenges facing academic data stewardship and the precarity of research careers more generally. Some of the above-mentioned immediate benefits also have a positive impact in the long term.
Skills transfer, insightful innovation, and cultural change
The embedded RDM training and competency building can be an effective way of improving things like FAIR awareness and promoting open science practices. More practically, it trains doctoral students in optimizing RDM workflows and integrating RDM into their research practices. This, in turn, will have positive benefits when they reach the point in their careers that they are actively involved in training and supervising future researchers by transferring their skills and best practices. The combination of working as a researcher and data steward would lead to an insightful and critical view on discipline-specific RDM challenges and practices. New innovations in RDM and open science could be built based on that. The embedded role also addresses researchers’ responsibilities in RDM for early career academics. By facilitating and promoting training in RDM practices early on, it gives formalized support to bottom-up initiatives promoting improved RDM practices among researchers. The new generation of academics will embrace the culture of open science.
Alternative academic career path
Finally, it can be an important step in working towards diversifying career paths in academia and modernizing the academic system of recognition and rewards. With formalized roles, doctoral student data stewards can more easily use the skills achieved through the programme on their CVs. By creating and supporting this role in doctoral training, universities address the importance of data stewardship and open science practices. This helps to formally establish professional roles in academia that directly contribute to science, and offers one concrete alternative path forward for PhDs to stay in academia.
Challenges
Several practical challenges come along with the implementation of this recipe, which requires attention and joint efforts from multiple stakeholders:
It still requires financial and organizational resources. In particular, the institutions need to figure out how the PhD contract could be extended and processed in the institutional system and complied with HR-related policies. There is also a need for agreements between the PhDs and their supervisors/departments. Furthermore, RDM capacity for supervising and coordinating these embedded Data Stewards should be planned too.
There is no guarantee that recruiting doctoral students will be successful nor properly match the needs of researchers/research groups.
Despite promising potentials, the RDM support would still be possibly perceived as an additional task allocated to doctoral students. There is no guarantee of a career path in academia from becoming the Data Stewards.
Call for actions
The landscape of academic Data Stewardship has been fast changing and the RDM community has been growing since The Amsterdam Call for Action on Open Science back in 2016. It is time to assess the growth of the profession and the dynamic needs of the research community,
We sincerely hope that policymakers and different stakeholders can start taking mini yet concrete steps on recognizing and professionalizing Data Stewardship and Open Science, in particular:
Offer sustainable funding models that allow doctoral students to formally work as Data Stewards as part of their doctoral education, like teaching and other research services
Formally recognize the contribution of Data Stewardship in research
Support the professional development of Data Stewards with proper training and education
Recognize Data Stewardship as a potential career path in academia
As part of the Turing Way, we co-organised an event at the TU Delft library! This event was part of the Book Dash that is organised twice a year. During each Book Dash people come together to work on the Turing Way and add their contributions within a short period (hence why it is called a ‘dash’). A large part of the event takes place online, and this year there were in-person hubs in London at the Alan Turing Institute and at TU Delft.
At the TU Delft hub we had several people joining from the Dutch eScienceCenter as well as more internationally based that were interested in Open Hardware to work together to include a more extensive guide on Open Hardware in The Turing Way!
What did we work on?
Tanya worked on including artists and civil society/community-based organisations as alternative ways for Open Communication of research process and research results. The subsections serve to start the conversation and would benefit from feedback of others with experience with both, artists and civil society/communities, and cases to demonstrate different perspectives.
Azin got familiar with the Turing Way and had discussions with Barbara on ‘Code linting’.
The Open Hardware team (Angela, Santosh, Julien, Sacha, Moritz, Julieta, Nico) worked together on a new Open Source Hardware chapter, including two illustrations.
Barbara and Pablo worked on an old Pull Request on error message management. During the Dash Barbara commented that “This more than anything makes me believe in Git”, as the pull request was already three years old!
The Delft Hubbers demonstrated a fiery passion about Climate Change in our break discussions (yes, we did try to use the breaks to focus on things other than Book Dash work) and took extra care to follow the Code of Conduct. We promised to work with the university, such that all future events organised at the TU Delft will avoid the use of disposable cups and Nescafé machines… We had a great time getting to know each other in an informal atmosphere and testing the bounds of our biases through jokes. The hub attracted a bunch of Open Science enthusiasts from both the Netherlands and Germany, which inevitably led to a lot of collaboration ideas for the future and future-focused discussions.
The thematic focus (on Open Hardware) was a real success, allowing for specific networking and concrete collaborative work. Informal conversations did naturally sprout the idea to have another thematic focus for a future Book Dash in the Netherlands. A proposed theme is Citizen Science and a guide on “how to Citizen Science”. Thoughts?
The Research Services department of the Library has recently expanded to four teams, and is appointing some new heads. I have added short descriptions of core tasks for each team
Yan Wang has been appointed Head of Research Data and Software. This team has responsibility for
Madeleine de Smaele is the Interim Director of 4TU.ResearchData. (We are currently in the recruitment process for a full-time Director) This team has responsibility for the