
Category: conferences
Share, Inspire, Impact: TU Delft DCC Showcase Event
Author: Ashley Cryan, Data Manager , TU Delft Digital Competence Centre

Tuesday, October 12 was a momentous day for the TU Delft Digital Competence Centre (DCC). A little more than a year after the new research support team of Data Managers and Research Software Engineers came together for the first time, the Share, Inspire, Impact: TU Delft DCC Showcase Event took place, co-hosted by the TU Delft Library’s Research Data Services team, ICT- R&D / Innovation and the TU Delft High Performance Computing Centre (DHPC).
Researchers from across all faculties at the University joined the virtual live event, aimed at sharing results achieved and lessons learned from collaborating with members of the DCC during hands-on support of projects involving research data and software challenges. The exchange of experiences and ideas that followed was a true reflection of the ingenuity and collaborative spirit that connects and uplifts the entire TU Delft community.
Inspiring opening words from TU Delft Library Director Irene Haslinger invited researchers, staff and representatives from academic communities like Open Science Community Delft and 4TU.ResearchData to reflect together and help distill a common vision for the future of the DCC. The DCC’s core mission is clear: to help researchers produce FAIR (Findable, Accessible, Interoperable, and Reusable) data, improve research software, and apply suitable computing practices to increase the efficiency of the research process. Event chairperson Kees Vuik and host Meta Keijzer-de Ruijter guided the discussion based on the fundamental question, how best can researchers and support staff work together to achieve these important goals in practice?
“In the effort to promote and support FAIR data, FAIR Software, and Open Science, everyone has a role.”
– Manuel Garcia Alvarez, TU Delft DCC
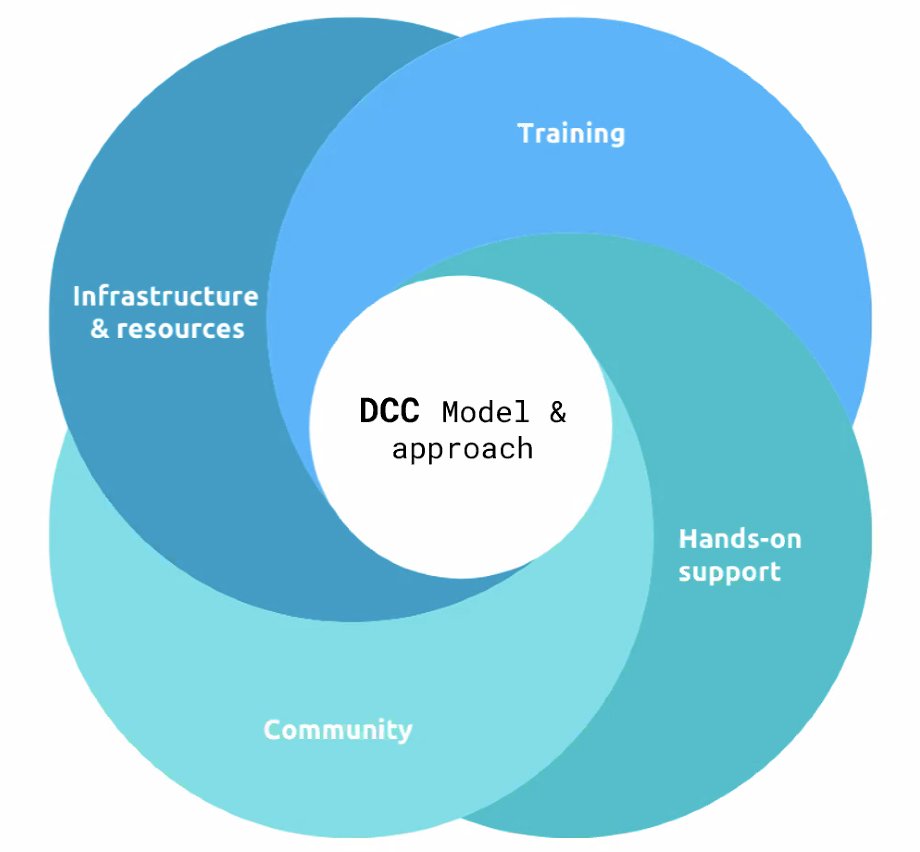
Manuel Garcia Alvarez began with a presentation on the DCC working model and approach to the above question. After a year of trialling process-in-practice, the support team model is defined by four building blocks based on observed researchers’ needs: Infrastructure and Resources, Training, Hands-On Support, and Community. Researchers require sufficient access to and understanding of IT infrastructure and resources available through the University – robust computing facilities, secure data storage solutions, platforms for digital collaboration – in order to facilitate analysis workflows and achieve their research goals. The DCC support team works closely with staff in the ICT department to ensure that researchers can select, deploy, and manage computational resources properly to support their ongoing needs. Hands-on support is offered by the DCC in the form of support projects which last a maximum of six months, working closely in collaboration with research groups. This type of support blends the domain expertise of the researchers with the technical expertise of the DCC support team members to address specific challenges related to FAIR data/software and computational needs. Researchers can request this type of dedicated support by submitting an application through the DCC website (calls open several times per year).
Of course, the DCC support team came into existence as part of a broader community focused on supporting researchers’ digital needs: one that is made up of the faculty Data Stewards, ICT Innovation, Library Research Services, the DHPC, and the Library team for Research Data Management. The DCC contributes to ongoing training initiatives like Software and Data Carpentry workshops that equip researchers with basic skills to work with data and code, as well as designs custom training in the context of hands-on support provided to research groups. One such example is the “Python Essentials for GIS Learners” workshop, designed by the DCC during support of a project in ABE focused on shifting to programmatic and reproducible analysis of historical maps (the full content of this course is freely available on GitHub).
The program featured a lively Round Table discussion between researchers who received hands-on support from the DCC and the DCC members that supported them, focusing on the DCC model of co-creation to help researchers solve complex and pressing data- and software-related challenges. Researcher panelists Omar Kammouh, Carola Hein, and Liedewij Laan shared their experience working alongside DCC members Maurits Kok, Jose Urra Llanusa, and Ashley Cryan in a spirited hour of moderated discussion. Each researcher panelist was invited first to introduce the project for which they received DCC support in the context of the challenges that inspired them to submit an application to the DCC. Then, DCC members were invited to elaborate on these challenges from their perspective and highlight the solutions implemented in each case. The DCC style of close collaboration over a period of six months was positively received by researchers who found the engagement productive and supportive of their research data management and software development process. The need to develop a kind of “common language” between members of the DCC and research group across domain and technical expertise was highlighted in several cases, and served to clarify concepts, strengthen trust and communication, and build knowledge on both sides that aided in the delivery of robust solutions. Practical benefits from the application of the FAIR principles to researchers’ existing workflows and outputs were also mentioned across cases. Collaboration with the DCC enabled researchers to share their data and software more broadly amongst direct collaborators and externally to the wider international research community. The last question of this discussion was whether Omar, Carola and Liedewij would recommend that other researchers at TU Delft apply for hands-on support from the DCC: the answer was an emphatic yes!
Attendees then had the option to join one of the four thematic breakout sessions: Community Building; Digital Skills and Training; Looking Ahead: Impactful Research Competencies of the Future; and Infrastructure, Technology and Tooling for Scientific Computing. Moderators Connie Clare and Emmy Tsang in the Community Building breakout room invited research support professionals from across universities and countries to share their experience being part of scientific communities, and found that recurring themes of knowledge sharing, inclusivity, friendship and empowerment wove throughout most people’s positive experiences. The discussion in the Digital Skills and Training room, moderated by Meta Keijzer-de Ruijter, Paula Martinez Lavancy, and Niket Agrawal, touched upon existing curricula and training programs available at TU Delft to help researchers and students alike develop strengths in fundamental digital skills like programming and version control. In the Looking Ahead room, moderators Alastair Dunning and Maurits Kok led a lively discussion on challenges related to rapidly advancing technology, and how the provision of ICT services and infrastructure solutions can avoid becoming a kind of “black box” to researchers. The Infrastructure, Technology and Tooling room, led by Jose Urra Llanusa, Kees den Heijer, and Dennis Palagin, discussed researchers’ need for IT infrastructure and technical support in the specific context of their research domain, including specialised tools and security measures that can help facilitate international collaboration. When the group came together in the main room to share summaries of each room’s discussion, the common themes of scalability, collaboration, and a balanced approach to centralised support emerged.
“Support staff need to always work in partnership with researchers. In the future, we need both central and local DCC support and collaboration to continue learning from each other.”
– Marta Teperek, Head of Research Data Services and 4TU.ResearchData at TU Delft
The closing words delivered by Rob Mudde, Vice-Rector Magnificus and Vice President Education, were a fitting end to a spirited day of reflection and discussion. Acknowledging the work of many to bring the TU Delft Digital Competence Centre into reality and its ethos as a hug of knowledge, connection and inclusivity, he stated, “As a university, we are a big community – we stand on one another’s shoulders. It’s collective work that we do. You can see how the DCC engages across disciplines to help all go forward.”
The DCC extends its warm gratitude to all those who made the “Share, Inspire, Impact DCC Showcase Event” happen, in particular event planning leads Deirdre Casella and Lauren Besselaar, and all of the panelists, speakers, session leaders, and participants who made the discussion so engaging and memorable. The team looks forward to continuing to work with researchers in the TU Delft community and building capacity toward a shared vision for the future we can all be proud of.
Visit the TU Delft | DCC YouTube playlist to view testimonials of researchers and the DCC Event aftermovie (forthcoming).
International Digital Curation Conference, February 2020, Dublin (Ireland)

Over 300 participants gathered to talk on:
Collective Curation: the many hands that make data work.
The programme focused on the community: the various stakeholders that play a role in ensuring digital objects are properly created, managed and shared.
The 2day conference started with a very interesting keynote on the Internet of Things (IoT) from Francine Berman, Professor in Computer Science at Rensselaer Polytechnic Institute (RPI) and this year based at Harvard. The main message was: IoT can be Utopia or Dystopia, it is all up to us. The IoT will generate TBs of data. How do we cope with that? How do we prevent devices for being hacked? Where is the privacy when you drive in an automated vehicle? The car knows which music you listen to!!
I spoke with people engaged in the training of people and had the chance to promote the courses Essentials 4 Data Support course and the MOOC Delivering Research Data Services. We ran this MOOC last year Autumn and we rerun the MOOC, starting February 24. Last year we had over 1600 participants!! The poster was presented in a poster:

One of the session was on a risk catalogue that can be used to review data management plans. There are legal, privacy, ethical and technical risks. It makes the data management plan more a working document, knowing the risks and how to manage them.
Second day, February 18
The second day started with a keynote from Kostas Glinos, Head of Unit for Open Science at European Commission, in the directorate-general for Research & Innovation since 1 June 2019. He spoke on how responsible research data management will be key in mainstreaming Open Science policies under the next framework programme, Horizon Europe. In that programme mandatory data management plans for all projects that generate or collect research data, and by introducing data management considerations as an element on which applicants can be evaluated. One of the reasons is that the EU wants to improve trust between science and society by engaging citizens in co-designing and co-creating research.
Another presentation I liked was on gaming: Lego; Metadata for reproducibility. In short:
Build a vehicle with 13 bricks, document what you have built and take it apart again. Another group will then build the car again using the documentation. After building the cars are compared with another. This generates lots of discussions and can be used for talking on the importance of metadata.
I attended a session on the Privacy Impact Assessment (PIA) from the ICPSR. The PIA investigates the privacy issues concerning data. The ICPSR trains researchers to acquire a passport that approves access ta various databases, based on their training and credentials. Researchers acquire a passport where the level of access is mentioned.
An impression of the conference:

Sandra Collins (Director of the National Library of Ireland) on Collecting and Curating the National Memory was the last keynote speaker.
The Irish National Library collects memories to share the culture and story of a nation. In the past that were ‘physical’ memories: newspapers, books and also lottery tickets! But in the digital age, our life is more and more open and our personal memories are digital-born. The National Library collects nowadays more and more digital items, already more than 300.000 Irish websites! The National Library works together RDA and DCC in curating their collection. And many volunteers to provide metadata to all kind of items.
Some conclusions of this iDCC:
– There is a strong focus on FAIR, and on how to put these principles into practice
– Reliability is becoming more and more an issue
– More and more data are generated, as more and more devices are connected. We as a society need to take care of that, in good collaboration with government and academia.
The next iDCC will be organised in collaboration with the RDA Plenary, Edinburgh, UK, from 20th to 22nd April 2021.
EUA-FAIRsFAIR focus group meeting – addressing development of competences for (FAIR)data management and stewardship.
By Paula Martinez-Lavanchy
On the 19th of November I joined the meeting of the EUA-FAIRsFAIR focus “Teaching (FAIR) data management and stewardship” at the University of Amsterdam. In this post I summarized my key reflections of what happened during the meeting.
For those who are not yet familiar with FAIRsFAIR, it is an European project that started in March 2019 with the aim “to supply practical solutions for the use of the FAIR data principles throughout the research data life cycle. Emphasis is on fostering FAIR data culture and the uptake of good practices in making data FAIR.” The project has four main areas of work: ‘Data Practices’, ‘Data Policy’, ‘Certification’ (repositories) and ‘Training, Education and Support’. The meeting in Amsterdam was part of the activities of this last area, and specifically part of Work Package 7 of the project “FAIR Data Science and Professionalisation”. The main organizer of the event was the European University Association (EUA).
FAIRsFAIR project aims to be deeply connected with the European Open Science Cloud (EOSC) through a dedicated Synchronisation Force, which will offer coordination and interaction opportunities between various stakeholders, including the EOSC. It was not clear to me how exactly will the input of the project be used/adopted by EOSC in practice. However, the EOSCpilot work on skills was part of the presentations we saw, which suggest that the deliverables of FAIRsFAIR project are meant to become a building block of the EOSC, and not yet another layer of the cake of FAIR.
The various initiatives related to RDM training and FAIR data skills
The meeting started with five presentations that introduced the audience to different initiatives regarding or related to Research Data Management (RDM) training and/or FAIR data skills. Since we already talked about layers, I would divide the presentations in two: Framework initiatives and Implementation initiatives.
Framework initiatives: where the goal is to define the skills/competences that data scientists, data stewards and researchers should acquire around data management and to build up training curricula. There was a dedicated presentation about the EDISON project (Yuri Demchenko – University of Amsterdam) and FAIR4S (Angus Whyte – Digital Curation Centre – DCC). However, many other initiatives related to RDM skills and competences were mentioned: RDA Education & Training in Data Handling IG, Skills Framework for Information Age (SFIA), Competency Matrix for Data Management Skills (Sapp Nelson, M – Purdue), Open Science Careers Assessment Matrix, Towards FAIR Data Steward as a profession for the Lifesciences”. Kind of impressive and overwhelming to see the amount of groups working in the RDM training field.
Implementation initiatives: I call them implementation initiatives because these are initiatives already providing training or they are in the planning of creating an education program.

It was very interesting to hear about the work done by ELIXIR (Celia van Gelder – DTL/ELIXIR-NL), which is running training events for researchers, developers, infrastructure operators and trainers in the Life Sciences. ELIXIR also have a consolidated train-the-trainer- programme that provides training skills and have developed a really nice platform (TESS) where they announce training, make training materials available, but also provide guidance on how to build training.
We also had the opportunity to hear about the “National Coordination of Data Steward Education in Denmark” (Michael Svendsen – Danish Royal Library). They used a survey approach to investigate the landscape of expected skills that Data Stewards should have (results to be published soon). Based on this, the Danish Royal Library together with the University of Copenhagen, are planning to design a Data steward Education curriculum (launch 2021) and drafting a specific training module for the study program of librarians.
In summary, the terms ‘training’ and ‘education’ were used in the different presentations, but also many target groups and many types of skills with a different degree of relevance depending on the project or the initiative working on it. While this diversity was impressive, it felt somewhat difficult to understand the rationale for all these parallel projects and approaches, and how will they all lead to a coherent, agreed, pan-European framework for RDM skills and competences.
Advantages, disadvantages, challenges and opportunities
In the afternoon session we had break out discussions where 4 topics were proposed:
- Teaching RDM/FAIR at Bachelor/Master level
- Addressing RDM/FAIR at Doctoral/Early-career researcher level
- Generic Data Stewardship and FAIR data competences
- Disciplinary/Domain-specific Data Stewardship and FAIR data competences

We had two sessions of discussion, so each of us had the opportunity to join two different topics. For each topic we discussed advantages/disadvantages, good practices, missed opportunities, challenges, target audiences, possible synergies, etc. I joined topic 1 (Teaching RDM/FAIR at Bachelor/Master level) and 4 (Disciplinary/Domain-specific Data Stewardship and FAIR data competences). In both breakout groups we had rather broad discussions and exchange of knowledge, with more or less structure, but I found them very interesting and valuable. The organizers promised to report on the discussion results, so I will not duplicate their efforts. There will be a following post for sharing my own overall reflections about education and training on RDM. So to be continued.
Summary
What are the next steps for the FAIRsFAIR project with regards to skills and competences? The organizers intend to use the results of this meeting and the results collected in the “Consultation on EUA-FAIRsFAIR survey on research data and FAIR data principles”, a survey that they recently run, in order to define the activities of the project in the track of training and education. So hopefully more on this soon.
Update
The organizers of this event have recently shared a Short summary of the Focus Group workshop at https://www.fairsfair.eu/articles-publications/fairsfair-focus-group-university-amsterdam.
You can follow the progress of the FAIRsFAIR project looking at their deliverables page: https://www.fairsfair.eu/reports-deliverables or via Zenodo
TU Delft Research Data at the Research Data Alliance Plenary 14
By Marta Teperek, Paula Martinez-Lavanchy and Yan Wang

Research Data Alliance (RDA) is an international organisation dedicated to everything about research data. It has over 9,000 members world-wide and has a plenary meeting twice a year at various locations around the globe. Marta Teperek, Paula Martinez-Lavanchy, Yan Wang and Esther Plomp* represented TU Delft Research Data Services and Data Stewards at RDA Plenary 14 meeting in Helsinki 23-25 October 2019 and are sharing their key contributions and take away messages.
Research Data Alliance Plenary meetings are always very rich with new content, innovative ideas, and offer plenty of opportunities for networking and collaboration – all evolving around research data management. The meeting consists not only of three days full of meetings of the various working and interest groups (multiple parallel sessions last from the very morning until late in the afternoon/evening!), but also other events: knowing that 500+ data experts attend each plenary meeting, there are always numerous co-located events. In addition, most people stay at a few hotels located close to the main conference venue, facilitating additional networking opportunities. Discussions often start at very early mornings (breakfast working meetings) and last until late evenings (networking dinners).
Marta, Paula and Yan decided to share a small selection of what we thought were our key contributions and take-away messages and explain why these are relevant to TU Delft.
Libraries for Research Data Interest Group
Marta is the co-chair of the Libraries for Research Data Interest Group (L4RD IG) and co-organised the group’s meeting during Plenary 14. Yan has presented the work looking at Engaging Researchers with Research Data.
What does this group do?
Libraries are actively developing new services in the digital environment, and in research data management in particular. The purpose of this interest group is to provide a forum for international data management experts to share practice and experience as RDM library services mature and to keep each other posted about the latest developments on data management.
Why is this important for TU Delft?
TU Delft wishes to be at the forefront of innovation when it comes to research data management. Being part of the group means not only being part of the network of international library experts on data management but also being at the centre of the newest developments and initiatives in RDM.
Related resources:
Research Data Management in Engineering
Paula is one of the co-chairs of Research Data Management in Engineering IG and co-organised the group’s kick-off meeting during Plenary 14.
What does this group do?
Engineering comprises a vast span of sub-disciplines including for example chemical, civil, electrical, and mechanical engineering. The research in Engineering is highly multidisciplinary, often involves close collaboration with industry and it generates a vast range of outputs from innovative materials to the production of software. Research data management practices within these sub-disciplines tend to be unaligned with e.g. open data initiatives/requirements and the implementation of the FAIR data principles. This group aims at changing the culture of handling data, creating awareness and bridging (sub-)communities and existing initiatives. It also aims at providing a platform for developing consensus on RDM best practices for engineering and to actively collaborate with other groups at RDA for adopting and/or adapting their outputs to be used by researchers in engineering.
Why is this important for TU Delft?
TU Delft has a strong focus on engineering and innovation. Our researchers are engaging more and more in Open Science and incorporating Research Data Management best practices within their workflows thanks to the work of our Data stewards. But, there are still some barriers to fully comply with the FAIR data principles e.g. the lack of metadata standards in engineering disciplines. Some concerns on how to balance the collaboration with industry and open science practices also exist. Through the involvement in this group, TU Delft hopes to overcome those barriers by working together with the research communities and institutions which are RDA members. After Plenary 14, the work of the group will focus on metadata standards, re-use of data and open science within engineering.
RDA also provides a great opportunity to link and disseminate the work done by TUDelft in the Conference of European Schools for Advanced Engineering Education and Research (CESAER) especially through the Task Force Open Science.
Related resources:
Birds of a Feather: Engaging Researchers with Research Data: What Works?
Marta organised a dedicated Birds of a Feather session: Engaging Researchers with Research Data: What Works? Yan presented a case study during the session.
What was this session about?
The objective of this meeting was to receive community feedback on the proposal to create the Engaging Researchers With Research Data Interest Group. So far, the group acted informally and gathered case studies on how academic institutions engage with researchers about research data. Selected case studies were published in the book “Engaging Researchers with Data Management: The Cookbook”. The group now wished to formalise its activities with the aim to continue information exchange about innovative activities, which facilitate researcher engagement with research data and to welcome other RDA members to join the group.
Why is this important to TU Delft?
In order to implement good RDM practice within research communities, a cultural shift is necessary. TU Delft has been actively investing in various strategies aiming to achieve cultural change, and have already benefited from advice and lessons learnt from other universities. For example, TU Delft’s Data Champions programme is a direct inspiration from the University of Cambridge. Through active participation in this group, TU Delft hopes not only to exchange practice and lessons learnt with other RDA members but also stay up to date with new tactics which could help us further increase engagement with our research communities.
Related resources:
- Engaging Researchers with Data Management: The Cookbook – book with case studies on how institutions can effectively engage with researchers about research data.
- Collaborative session notes with links to presentations
Birds of a Feather: Professionalizing data stewardship
Marta also co-organised another Birds of a Feather session on Professionalizing data stewardship.
What was this session about?
During this session, we discussed the various models used by institutions worldwide to provide data stewardship support to research communities. This was followed by a discussion about the need to professionalise data stewardship: to create job profiles, to agree on career progression, on the skills which data stewards need to have and many others. The participants agreed that these issues are beyond individual institutions or countries and are better to be addressed by a dedicated international group, such as RDA.
Why is this important to TU Delft?
TU Delft is at the forefront of data stewardship, which also means it is often the first one to deal with issues related to lack of recognition of data stewards as a dedicated profession: questions about remuneration, career progression, agreed set of skills and tasks are daily problems experienced by the data stewards and those coordinating the programme. Therefore, it is essential for TU Delft to find solutions to these problems, ideally through collaboration with a group of international experts on the topic.
Related resources:
- Data (Stewardship) Makes The Difference: Towards A Community-Endorsed Data Stewardship Profession – blog post by Connie Clare reporting from “Professionalizing Data Stewardship” session
- Collaborative notes from the session
- Link to slides
Education and Training on handling of research data IG
Paula is a member of the Education and Training on handling of research data IG and participated in the meeting of the group organized in Plenary 14.
What does this group do?
Research has become a highly data-intensive activity. Education programmes at universities have recognized that new skills for data analysis are needed and have started to include e.g. programming skills within their curricula. However, there is less focus on skills related to good management, documentation and preservation of data. The objective of this IG is the exchange of information about existing developments and initiatives and promotion of training/education to manage research data throughout the data lifecycle.
Why is this important for TU Delft?
TU Delft is intensively working in preparing its Open Science Strategic plan 2020-2024. One of the cross-cutting themes for all the project lines (Open Access; Open Publishing; FAIR Data; Open Software and Open Education) are ‘skills’. In this line, the Research Data Services team has recently published its Vision for Research Data Management Training at TU Delft. To implement this training vision in a sustainable way TU Delft must collaborate with those communities, organizations and projects that are already providing training and those who would like to get started. Besides exchanging knowledge with those relevant stakeholders, the involvement of TU Delft in this group is very relevant to collaboratively work on the development of training curricula and materials.
Related resources:
The International Research Data Community contributing to EOSC
One of the events which were co-located with RDA was the European Open Science Cloud (EOSC) meeting. The purpose of this meeting was to engage with the international research data community in the development of the EOSC. As a member of the EOSC FAIR Working Group, Marta was one of the co-organisers of one session of this meeting – discussion about FAIR practices across disciplines. Yan was the facilitator and rapporteur of the multidisciplinary research breakout group.
What was this session about?
During this session, members of various disciplinary communities within the EOSC split into separate discussion groups. In addition to covering the well-recognised disciplines like engineering, social science and medical science, there was also a dedicated group focusing on FAIR practices in multidisciplinary research.
The discussion groups provided feedback on FAIR practices within their disciplines: what do the communities already do to put FAIR into reality (e.g. do they have disciplinary standards, do they use disciplinary repositories for their research outputs), what are the societal and technical barriers preventing full implementation of FAIR principles and what could be done to overcome these. They also discussed what services/components within the EOSC require FAIR certification, and what metrics would be the most suitable for the different components identified.
Why is this important to TU Delft?
All members of the EOSC Working groups act as impartial advisors and do not represent the interests of the organisations they are affiliated with. The mission of the FAIR Working Group is to provide recommendations on the implementation of FAIR (Findable, Accessible, Interoperable, Reusable) practices within the EOSC. EOSC is a pan-European initiative and its success is dependant on the practical implementation of FAIR practices across all European research institutions. Given that TU Delft wants to be the frontrunner in the culture change towards better and FAIRer data management, the activities of the group are very important and relevant: it is essential that TU Delft researchers are able to fully participate in the EOSC.
Reflection
The above are just snapshots of what has happened during the last Plenary 14. Marta, Paula, Yan and Esther returned to TU Delft exhausted, but also very enthusiastic and full of new ideas on how to continue working on further improvement of research data management services at TU Delft. The Plenary 14 is now over and the next one is only in 6 months. However, this does not mean that nothing happens in the time being. To the contrary, the hard work has just begun. Members of working and interest groups continue their work in the period between plenaries – through teleconferences and other types of online collaboration. In-person group meetings at plenaries are important milestones used to review the work progress and jointly agree on new priorities. So Marta, Paula, Yan and Esther will be now busy contributing to the activities mentioned above.
What is really inspiring about RDA, and what makes it very unique compared with other conferences and meetings, is that it focuses on collaborative working – it’s not just another conference where people gather to listen to presentations. In RDA anyone can come up with an important problem, which needs to be solved. If there are enough people who wish to work together to find a solution to this problem, a new working group or interest group can be created, which will look for a solution. Collectively, RDA is a community of 9,000+ data experts worldwide, who are part of a myriad of working and interest groups. This set up truly allows the international community of data management professionals to solve their data management challenges collaboratively – and jointly come up with the best solutions.
Being part of RDA and actively participating in the working/interest groups allows TU Delft to stay close with the state of the art in research data management. It helps maintain the professionalism and a high level of expertise of TU Delft research data services, not only at the international RDM community level but also, more importantly, at our local level – when supporting our own researchers.
* – Esther of course also actively participated in the RDA meeting and contributed to several interest and working groups. Her contribution could not be included here due to conflicting annual leave schedules. This information might be added later.
Openness and Commercialisation: could the two go together?

Between 14 and 17 October 2019 I attended the Beilstein Open Science Symposium. As always, excellent, inspiring talks. This year’s talks related to openness and commercialisation were particularly interesting to me, so I would like to share some of my thoughts and observations.
Collaboration with industry is at the core of many research projects at Delft University of Technology. However, working with industry and commercialisation often entails secrecy and close protection of knowledge. At the same time, the University is also a public body, and a substantial proportion of its funding comes from taxpayers’ money. Research funded by the public should be shared as broadly as possible with the public. So how do these two come together? Is openness inherently antagonistic to commercialisation? Can there be a middle ground?
Industry, academia and the public as allies
Chas Bountra, the Pro-Vice-Chancellor for Innovation at the University of Oxford and the Chief Scientist at the Structural Genomics Consortium (SGC) provided a compelling example of how industry and academia can work together to find new medicines and address some of the most pressing healthcare problems in the society.
Bringing a new drug to market typically costs pharma companies several billion dollars. To ensure return on investment, pharmaceutical companies need to make successful drugs appropriately priced. This, in turn, might make life-saving medicines unaffordable to patients and healthcare providers. Why does it cost so much money to make new drugs? Chas explained that everyone seems to be working on similar drug targets: both industry and academia read the same papers, attend the same conferences, and come up with the same ideas in parallel. Secrecy of the research process means that no one shares negative outcomes of their studies (true for both academia and industry). As a result, only about 7.5% of potential cancer drugs which enter Phase I of clinical trials, make it to the market. This also means that successful drugs need to compensate in their price for all the unsuccessful ones.
Structural Genomics Consortium was created as a collaboration between academia, public funders and industry (nine big pharma companies) out of a desire to accelerate to find new medicines and to improve discovery of new drug targets. Resources from all partners are being pooled to make these to processes more efficient. In addition, the consortium works only on novel ideas – novel targets, which are not explored elsewhere. The consortium purifies human proteins, builds assays, works out 3D structures and creates tools: highly specific inhibitors against these new targets. And how to identify these novel targets? Members of the SGC consortium work with committees composed of experts in academia, industry and clinicians who donate their free time to help SGC decide which new targets to work on. Patient groups not only provide precious human material to work on (patient tissue) but also help identify the experts, as they know well which labs all over the world work on cures for their disease.
Why would all these stakeholders do all this work for the consortium? Because all the results, all the tools and molecules developed by SGC are made available for free to anyone willing to work on them. For academics this means new, robust research tools enabling innovative research. Pharma companies benefit because they get the chance to take these novel, highly specific molecules and turn them into successful drugs. Clinicians and patients are motivated by the collaboration as it brings hope for new medicines.
In the end, everyone benefits from openness and collaboration. By now over 70 molecules have been generated by SGC, which are made available to anyone interested in working on them.
Collaboration and openness at any scale speeds up innovation
The example of SGC is certainly inspiring. At the same time, perhaps a bit intimidating for others to follow. Establishing an open collaboration with nine big pharma companies and numerous academics and clinicians is certainly not an easy task to achieve, which must require a lot of trust and relationship building. What if you don’t yet have such connections? Or what if you are an early career researcher, who doesn’t yet have such connections?
I was greatly inspired by the talk of Lori Ferrins from Northeastern University. Lori is part of Michael Pollastri’s lab, which is working on neglected tropical diseases (NTDs). NTDs are a group of parasitic diseases, such as malaria or sleeping sickness, that disproportionately affect those living in poverty. Pharmaceutical companies are not interested in developing drugs for these diseases because there is no commercial incentive (return on investment rather unlikely). To address this issue, Lori and her colleagues collaborate with pharma companies and with other academic labs. Pharma companies provide access to their existing molecules and are then trying to repurpose these existing molecules into effective parasite growth inhibitors. Academics join in driven by their research interest.
However, not everyone in such collaboration is comfortable with going fully open. To address this issue and to enable cooperation nonetheless, the lab developed a shared database where all data and results are shared within the group of collaborators. In addition, various levels of sharing and collaboration are allowed to ensure that investigators are comfortable to work together. Lori’s story is, therefore, a beautiful example that flexibility can be essential and sharing can occur at various levels and scales. What’s most important is that collaboration and information exchange happens. This helps reduce duplication of effort (collaboration and division of labour instead of competition) and speeds up innovation.
Open source and commercialisation
Lastly, Frank Schuhmacher spoke about his impressive open hardware endeavour, which is to create an automated oligosaccharide synthesizer. An automated oligosaccharide synthesizer is a machine able to automate the multi-step synthesis reaction of longer saccharide molecules. Self-made synthesizer offers researchers a lot of flexibility: they can add and remove various components of the synthesizer, as necessary for a particular reaction. In addition, researchers are also fully in control if anything goes wrong (without relying on obscure block box mechanisms provided by commercial companies). Moreover, the automation of chemical reactions means more reproducible research.
Frank’s talk sparked a discussion about whether open hardware projects can become self-sustainable and whether they offer any commercialisation potential. And here inspiration from my TU Delft colleague Jerry de Vos, who is involved in Precious Plastics, came in very handy. Precious Plastics started as a collaboration between people who wanted to help recycle the ever-growing amount of plastic waste. They have built a series of machines, which are all modular and consist of simple components. Designs for these machines are available openly – meaning that anyone interested can re-use the design, build their own machines and contribute to plastic recycling. So where’s the money? The fact that everything is open, means that money can be anywhere one can think of. Some business might be started by making the machines needed to process plastics commercially available (in the end, not everyone will be interested in building them themselves). Others might want to create products for sale made from recycled plastics. In fact, lots of businesses have been started with this very idea and Precious Plastics website already has its own Bazaar where myriad of pretty things made from recycled plastics are sold to customers worldwide.
The philosophy behind is that the more people join in (driven by commercial prospects or not), the more plastic is recycled.
Mix and match
Concluding, while the view that commercialisation must entail secrecy seems to still dominate in academia, the three examples above are clear demonstrations that sharing and openness do not have to go against commercialisation. To the contrary, collaboration can speed up and facilitate innovation and provide new commercial opportunities. What is therefore needed is perhaps a will to experiment and to be flexible to come up with a value proposition which would be interesting enough to all partners to join in.
And importantly, effective sharing does not mean that everything must be made publicly available – any collaboration, at any level, is better than competition.
Digital notes, here I come – status update on the Electronic Lab Notebooks pilot project at TU Delft

Written by Marta Teperek, Esther Plomp, Yasemin Turkyilmaz-van der Velden
The Electronic Lab Notebook (ELN) project at TU Delft is now well under way. It was officially kicked-off during a meeting which took place on 18 April 2019 and it will last for 1 year. During this time, interested TU Delft researchers will be able to try out two different ELN products: ResearchSpace (RSpace) and eLABjournal. At the moment, 37 researchers from three different TU Delft faculties (Applied Sciences – AS); Mechanical, Maritime and Materials Engineering – 3mE; Civil Engineering and Geosciences – CEG) are participating in the trial.
Why was this project started?
Discussions about ELNs at TU Delft were initiated back in March 2018, when several ELN providers, as well as researchers interested in moving away from paper to digital lab note keeping, came along to the event on the topic. Feedback gathered during and after the event demonstrated the interest among researchers at TU Delft in ELNs.
Subsequently, a dedicated ELN working group was created by colleagues from the library, ICT and Faculties of AS and 3mE (Susan Branchett, Esther Maes, Esther Plomp, Marta Teperek and Yasemin Turkyilmaz-van der Velden). The group gathered some key requirements for ELN products (based on the needs indicated by the research community at TU Delft and consultations with colleagues at other universities) and shortlisted two suppliers (RSpace and eLABjournal) which were able to best meet these key requirements. All functionalities were described in details by the providers on 18 April and both products are now available to interested TU Delft researchers for testing.

Photo from the ELN kick-off meeting on 18 April 2019
What will happen next?
The ELN working group will gather feedback from researchers testing the two products during and after the trial:
- Early evaluation (1-3 months into the project) is currently taking place by gathering feedback about the initial user experience via informal meetings with researchers.
- Mid-term evaluation (6 months into the project) is scheduled to happen during a dedicated consultation meeting with ELN users at TU Delft on Tuesday 24th of September.
- Final evaluation of the two products, which might inform a future tender process, will happen at the end of April 2020, at the end of the trial.
Subsequently, the ELN working group will develop recommendations for the next steps aiming at providing ELN solutions at TU Delft. Summary of these recommendations will be published on the Open Working blog and shared with interested stakeholders (researchers, ICT, library, faculties).
How can I get involved?
If you are a TU Delft researcher and would like to take part in the trial, please get in touch with Esther Plomp or Yasemin Turkyilmaz-van der Velden, Data Stewards from the Faculty of AS and 3mE, respectively.
Further reading
There are great ambitions behind FAIR data but researchers are not on board with it yet
On 27 and 28 February 2019, I attended the NSF FAIR Hackathon Workshop for Mathematics and the Physical Sciences research communities held in Alexandria, Virginia, USA. I travelled to the event at the invitation of the TU Delft Data Stewards and with the generous support of the Hackathon organisers, Natalie Meyers and Mike Hildreth from the University of Notre Dame.
Participants were encouraged to register and assemble as duos of researchers and/or students along with a data scientist and/or research data librarian. I was invited, as a data librarian with a research background in the physical sciences, to form a duo with Joseph Weston, a theoretical physicist by background and a scientific software developer at TU Delft, who is also one of the TU Delft Data Champions.
I presented about the Hackathon at the last TU Delft Data Champions meeting. The presentation is available via Zenodo. All the presentations and materials from the FAIR Hackathon are also publicly available. The FAIR data principles are defined and explained here. This blog post aims to offer some of my views and reflections on the workshop, as an addition to the presentation I gave at the Data Champions meeting on 21 May 2019.
The grand vision of FAIR
The workshop’s keynote presentation, given by George Strawn, was one the highlights of the event for me. His talk set clearly and authoritatively what is the vision behind FAIR and the challenges ahead. Strawn’s words still ring in my head: “FAIR data may bring a revolution on the same magnitude as the science revolution of the 17th century, by enabling reuse of all science outputs – not just publications.” Drawing parallels between the development of the internet and FAIR data, Strawn explained: “The internet solved the interoperability of heterogeneous networks problem. FAIR data’s aspiration is to solve the interoperability of heterogeneous data problem.” One computer (“the network is the computer”) was the result of the internet, one dataset will be FAIR’s achievement. FAIR data will be a core infrastructure as much as the internet is today.
“The internet solved the interoperability of heterogeneous networks problem. FAIR data’s aspiration is to solve the interoperability of heterogeneous data problem.” — George Strawn
Strawn warned that it isn’t going to be easy. The challenge of FAIR data is ten times harder to solve than that of the internet, intellectually but also with fewer resources. Strawn has strong credentials and track record in this matter. He was part of the team that transitioned the experimental ARPAnet (the precursor to today’s internet) into the global internet and he is part of the global efforts trying to bring about an Internet of FAIR Data and Services. In his view, “scientific revolution will come because of FAIR data, but likely not in a couple of years but in a couple decades.”
Researchers do not know about FAIR
Strawn referred mainly to technical and political challenges in his presentation. One of the challenges I encounter in my daily job as a research data community manager is not technical in nature but rather cultural and sociological: how to get researchers engaged with FAIR data and how to make them enthusiastic to join the road ahead? Many researchers are not aware of the FAIR principles, and those who are, do not always understand how, or are willing, to put the principles into practice. As reported in a recent news item in Nature Index, the 2018 State of Open Data report, published by Digital Science, found that just 15% of researchers were “familiar with FAIR principles”. Of the respondents to this survey who were familiar with FAIR, only about a third said that their data management practices were very compliant with the principles.
The workshop tried to address this particular challenge by bringing together researchers in the physical sciences, experts in data curation and data analysts, FAIR service providers and FAIR experts. About half of the participants were researchers, mainly in the areas of experimental high energy physics, chemistry, and materials science research, at different stages in their careers. Most were based in the US and funded by NSF.
These researchers were knowledgeable about data management and for the most part familiar with the FAIR principles. However, the answers to a questionnaire sent to all participants in preparation for the Hackathon, shows that even a very knowledgeable and interested group of participants, such as this one, struggled when answering detailed questions about the FAIR principles. For example, when asked specific questions about provenance metadata and ontologies and/or vocabularies, many respondents answered they didn’t know. As highlighted in the 2018 State of Open Data report, interoperability, and to a lesser extent re-usability, are the least understood of the the FAIR principles. Interoperability, in particular, is the one that causes most confusion.
Chasing windmills?
There were many opportunities during the workshop to exchange ideas with the other participants and to learn from each other. There was much optimism and enthusiasm among the participants, but also some words of caution, especially from those who are trying to apply the FAIR principles in practice. The PubChem use case “Making Data Interoperable”, presented by Evan Bolton from the U.S. National Center for Biotechnology Information, was a case in point. It could be said, as noted by one of the participants, that the chemists “seem to really have their house in order” when it comes to metadata standards. Not all communities have such standards. However, when it comes to “teaching chemistry to computers” – or put in other words, to make it possible for datasets to be interrogated automatically, as intended by the FAIR principles – Bolton’s closing slide hit a more pessimistic note. “Annotating and FAIR-ifying scientific content can be difficult to navigate”, Bolton noted, and it can feel like chasing windmills. “Everything [is] a work in-progress” and “what you can do today may be different from tomorrow”.

Closing slide in Evan Bolton’s presentation “Making Data Interoperable: PubChem Demo/Use Case” https://osf.io/6mxrk/
What can individual researchers do?
If service providers, such as PubChem, are struggling, what are individual researchers to do? The best and most practical thing a researcher can do is to obtain a persistent identifier (e.g. a DOI) by uploading data to a trusted repository such as the 4TU.Centre for Research Data archive, hosted at TU Delft, or a more general archive such as Zenodo. This will make datasets at the very least Findable and Accessible. Zenodo conveniently lists on its website how it helps datasets comply with the FAIR principles. The 4TU.Centre for Research Data, and many other repositories, offer similar services when it comes to helping make data FAIR.
Acknowledgments
I am grateful to the University of Notre Dame for covering my travel costs to the MPS FAIR Hackathon. Special thanks to Natalie Meyers from the University of Notre Dame, and Marta Teperek, Yasemin Turkyilmaz-van der Velden and the TU Delft Data Stewards for making it possible for me to attend.
Maria Cruz is Community Manager Research Data Management at the VU Amsterdam.
Reflections on Research Assessment for Researcher Recruitment and Career Progression – talking while acting?

Written by: Marta Teperek, Maria Cruz, Alastair Dunning
On 14 May 2019, we (Marta Teperek & Alastair Dunning from TU Delft, and Maria Cruz from VU Amsterdam) attended the “2019 workshop on Research Assessment in the Transition to Open Science”, organised in Brussels by the European University Association. The event accompanied the launch of the Joint Statement by the European University Association and Science Europe to Improve Scholarly Research Assessment Methodologies.
During the day we had a full agenda of valuable presentations and discussions on the topic of research assessment. Colleagues from several European universities presented case studies about current efforts at their institutions. All the presentations are available on the event’s website. Therefore, in this blog post, we don’t discuss individual talks and statements but offer some wider reflections.
Extreme pressure is not conducive to quality research
The first notion, repeated by several presenters and participants, was that the extreme work pressure contemporary academics face is not conducive to high-quality research. To succeed under the current rewards and incentives system, focusing on finding answers to explain natural phenomena through series of questions and testing and following the principles of scientific methodology, as 19th century scientists did, is not enough; 21st century researchers need instead to concentrate on publishing as many papers as possible, in certain journals, and on securing as many grants as possible.
Such pressure, the panellists at the event continued, limits the time available for creative thinking; selects for work that advances career progression to the detriment of work that benefits society and truly advances scholarly knowledge; and drives out young researchers, with adverse effects on the equality and diversity in science.

Figure showed by Eva Mendez during her presentation comparing a 19th century scientist with a 21st century academic. Source: https://www.euroscientist.com/?s=current+reward+system
You do not need to be a superhero – the importance of Team Science
Extreme work pressure has multiple causes. One significant factor is that academics are currently required to excel at everything they do. They need to do excellent research, publish in high impact factor journals, write and secure grants, initiate industry collaborations, teach, supervise students, lead the field, and much more. Yet it is rare for one person to have all the necessary skills (and time) to perform all these tasks.
Several talks proposed that research assessment shouldn’t focus on individual researchers, but on research teams (‘Team Science’). In this approach, team members get recognition for their diverse contributions to the success of the whole group.
The Team Science concept is also linked to another important aspect of research evaluation, which is leadership skills. In a traditional research career progression, academics who get to the top of their career ladder are those who are the most successful in doing research (traditionally measured in a number of publications in high impact factor venues). This does not always mean that those researchers had the leadership skills (or had the opportunity to develop them) that are necessary to build and sustain collaborative teams.
Rik Van de Walle, Rector of Ghent University in Belgium, emphasised this by demonstrating that in their new way of assessing academics, there will be a strong focus on the development of leadership skills, thereby helping sustain and embed good research.
“Darling, we need to talk”
There was a strong consensus about the necessity of continuous dialogue while revising the research assessment process. Researchers are the main stakeholders affected by any changes in the process, and therefore they need to be part of the discussions around changing the rewards system, rather than change being unilaterally decided by funders, management and HR services. To be part of the process, researchers need to understand why the changes are necessary and share the vision for change. As Eva Mendez summarised, if there is no vision, there is confusion. Researchers need to share this vision, as otherwise, they can indeed become confused and frustrated about attempts to change the system.
In addition, research assessment involves multiple stakeholders, and because of that, all these different stakeholders need to be involved and take actions in order for successful systemic changes to be implemented. Consultations and discussions with all these stakeholders are necessary to build consensus and shared an understanding of the problems. Otherwise, efforts to change the system will lead to distrust and frustration, as summarised by Noemie Aubert Bonn with her ‘integrity football’ analogy, where no one wishes to take the responsibility for the problem.

“Integrity football” by Noemie Aubert Bonn. Source: https://eua.eu/component/attachments/attachments.html?task=attachment&id=2176
… while acting!
At the same time, Eva Mendez reminded us that just talking and waiting for someone else to do something else will also lead to disappointment. She thought that more stakeholders should act and start implementing changes in their own spheres of influence. She suggested that everyone should ask themselves the question “What CAN I do to… change the reward system?”. She provided some examples: PlanS as an important initiative by funding bodies, and the consequent pledges by individual researchers on their plans of PlanS adoption, or the FOS initiative – Full Open Science Research Group, which is designed for entire research groups wishing to commit to practising Open Science.
Conclusions – so what are we going to do?
All three of us who attended the event are working in research data support teams at university libraries. We are not directly involved in research evaluation and we are grateful to our libraries who allowed us to participate in this event to broaden our horizons and deepen our interests. That said, we reflected on Eva’s call for action and thought that besides writing a blog post, we could all contribute at least a little bit to a change in the system.
Here are our top resolutions:
- Marta will work on better promotion and recognition of our Data Champions at TU Delft – researchers who volunteer their time to advocate good data management practices among their communities;
- Alastair will lead the process of implementing an updated repository platform for 4TU.Center for Research Data, which will give researchers better credit and recognition for research data they publish;
- Maria will kick off the Data Conversations series at VU Amsterdam, which will provide a forum for researchers to be recognised for the research data stories they share with others.
In addition, whenever we have a chance, we will keep reminding ourselves and our colleagues about the importance of rewarding quality, and not quantity, in research. An example of that was the VU Library Live “Rethinking the Academic Reward System” talk show and podcast held at the VU Amsterdam on 14 March 2019, which revolved around the question of how to change the academic reward to facilitate research that is open and transparent and contributes to solving key societal issues.
Additional resources
The main obstacles to better research data management and sharing are cultural. But change is in our hands

This blog post was originally published by the LSE Impact Blog.
Recommendations on how to better support researchers in good data management and sharing practices are typically focused on developing new tools or improving infrastructure. Yet research shows the most common obstacles are actually cultural, not technological. Marta Teperekand Alastair Dunning outline how appointing data stewards and data champions can be key to improving research data management through positive cultural change.
This blog post is a summary of Marta Teperek’s presentation at today’s Better Science through Better Data 2018 event.
By now, it’s probably difficult to find a researcher who hasn’t heard of journal requirements for sharing research data supporting publications. Or a researcher who hasn’t heard of funder requirements for data management plans. Or of institutional policies for data management and sharing. That’s a lot of requirements! Especially considering data management is just one set of guidelines researchers need to comply with (on top of doing their own competitive research, of course).
All of these requirements are in place for good reasons. Those who are familiar with the research reproducibility crisis and understand that missing data and code is one of the main reasons for it need no convincing of this. Still, complying with the various data policies is not easy; it requires time and effort from researchers. And not all researchers have the knowledge and skills to professionally manage and share their research data. Some might even wonder what exactly their research data is (or how to find it).
Therefore, it is crucial for institutions to provide their researchers with a helping hand in meeting these policy requirements. This is also important in ensuring policies are actually adhered to and aren’t allowed to become dry documents which demonstrate institutional compliance and goodwill but are of no actual consequence to day-to-day research practice.
The main obstacles to data management and sharing are cultural
But how to best support researchers in good data management and sharing practices? The typical answers to these questions are “let’s build some new tools” or “let’s improve our infrastructure”. When thinking how to provide data management support to researchers at Delft University of Technology (TU Delft), we decided to resist this initial temptation and do some research first.
Several surveys asking researchers about barriers to data sharing indicated that the main obstacles are cultural, not technological. For example, in a recent survey by Houtkoop at el. (2018), psychology researchers were given a list of 15 different barriers to data sharing and asked which ones they agreed with. The top three reasons preventing researchers from sharing their data were:
- “Sharing data is not a common practice in my field.”
- “I prefer to share data upon request.”
- “Preparing data is too time-consuming.”
Interestingly, the only two technological barriers – “My dataset is too big” and “There is no suitable repository to share my data” – were among three at the very bottom of the list. Similar observations can be made based on survey results from Van den Eynden et al. (2016) (life sciences, social sciences, and humanities disciplines) and Johnson et al. (2016) (all disciplines).
At TU Delft, we already have infrastructure and tools for data management in place. The ICT department provides safe storage solutions for data (with regular backups at different locations), while the library offers dedicated support and templates for data management plans and hosts 4TU.Centre for Research Data, a certified and trusted archive for research data. In addition, dedicated funds are made available for researchers wishing to deposit their data into the archive. This being the case, we thought researchers may already receive adequate data management support and no additional resources were required.
To test this, we conducted a survey among the research community at TU Delft. To our surprise, the results indicated that despite all the services and tools already available to support researchers in data management and sharing activities, their practices needed improvement. For example, only around 40% of researchers at TU Delft backed up their data automatically. This was striking, given the fact that all data storage solutions offered by TU Delft ICT are automatically backed up. Responses to open questions provided some explanation for this:
- “People don’t tell us anything, we don’t know the options, we just do it ourselves.”
- “I think data management support, if it exists, is not well-known among the researchers.”
- “I think I miss out on a lot of possibilities within the university that I have not heard of. There is too much sparsely distributed information available and one needs to search for highly specific terminology to find manuals.”
It turns out, again, that the main obstacles preventing people from using existing institutional tools and infrastructure are cultural – data management is not embedded in researchers’ everyday practice.
How to change data management culture?
We believe the best way to help researchers improve data management practices is to invest in people. We have therefore initiated the Data Stewardship project at TU Delft. We appointed dedicated, subject-specific data stewards in each faculty at TU Delft. To ensure the support offered by the data stewards is relevant and specific to the actual problems encountered by researchers, data stewards have (at least) a PhD qualification (or equivalent) in a subject area relevant to the faculty. We also reasoned that it was preferable to hire data stewards with a research background, as this allows them to better relate to researchers and their various pain points as they are likely to have similar experiences from their own research practice.
Vision for data stewardship
There are two main principles of this project. Crucially, the research must stay central. Data stewards are not there to educate researchers on how to do research, but to understand their research processes and workflows and help identify small, incremental improvements in their daily data management practices.
Consequently, data stewards act as consultants, not as police (the objective of the project is to improve cultures, not compliance). The main role of the data stewards is to talk with researchers: to act as the first contact point for any data-related questions researchers might have (be it storage solutions, tools for data management, data archiving options, data management plans, advice on data sharing, budgeting for data management in grant proposals, etc.).
Data stewards should be able to answer around 80% of questions. For the remaining 20%, they ask internal or external experts for advice. But most importantly, researchers no longer need to wonder where to look for answers or who to speak with – they have a dedicated, local contact point for any questions they might have.
Data Champions are leading the way
So has the cultural change happened? This is, and most probably always be, a work in progress. However, allowing data stewards to get to know their research communities has already had a major positive effect. They were able to identify researchers who are particularly interested in data management and sharing issues. Inspired by the University of Cambridge initiative, we asked these researchers if they would like to become Data Champions – local advocates for good data management and sharing practices. To our surprise, more than 20 researchers have already volunteered as Data Champions, and this number is steadily growing. Having Data Champions teaming up with the data stewards allows for the incorporation of peer-to-peer learning strategies into our data management programme and also offers the possibility to create tailored data management workflows, specific to individual research groups.
Technology or people?
Our case at TU Delft might be quite special, as we were privileged to already have the infrastructure and tools in place which allowed us to focus our resources on investing in the right people. At other institutions circumstances may be different. Nonetheless, it’s always worth keeping in mind that even the best tools and infrastructures, without the right people to support them (and to communicate about them!), may fail to be widely adopted by the research community.
